Read Parquet In Pandas
Read Parquet In Pandas - Result = [] data = pd.read_parquet(file) for index in data.index: Web 1.install package pin install pandas pyarrow. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. When using the 'pyarrow' engine and no storage options. While csv files may be the. Web september 9, 2022. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Using pandas’ read_parquet() function and using pyarrow’s. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Web in this article, we covered two methods for reading partitioned parquet files in python:
Web 1.install package pin install pandas pyarrow. Web september 9, 2022. Using pandas’ read_parquet() function and using pyarrow’s. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. When using the 'pyarrow' engine and no storage options. While csv files may be the. Web in this article, we covered two methods for reading partitioned parquet files in python: Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Result = [] data = pd.read_parquet(file) for index in data.index:
When using the 'pyarrow' engine and no storage options. Web september 9, 2022. Using pandas’ read_parquet() function and using pyarrow’s. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Web 1.install package pin install pandas pyarrow. Result = [] data = pd.read_parquet(file) for index in data.index: Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. Web in this article, we covered two methods for reading partitioned parquet files in python: While csv files may be the.
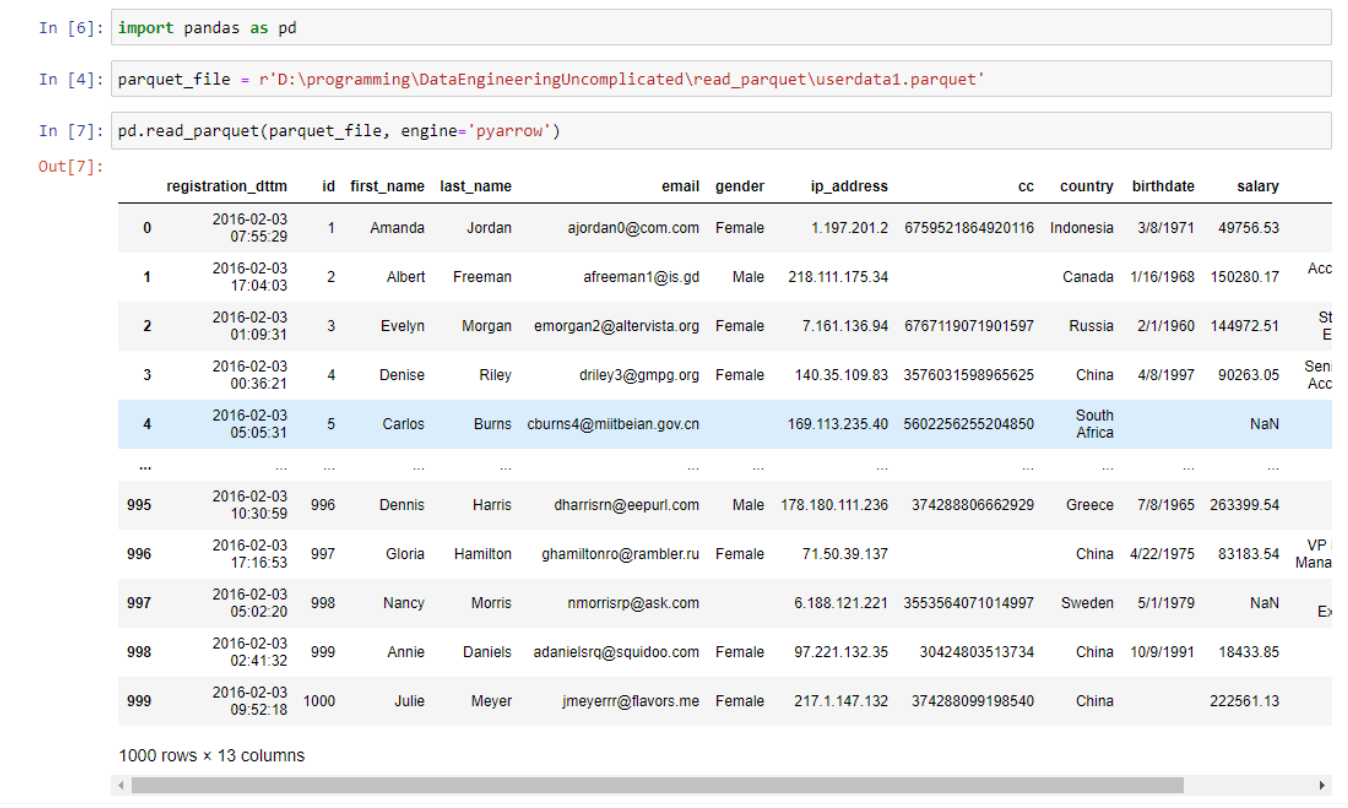
How to read (view) Parquet file ? SuperOutlier
Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. When using the 'pyarrow' engine and no storage options. Web in this article, we covered two methods for reading partitioned parquet files in python: Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Result = [] data = pd.read_parquet(file) for index in data.index:

python Pandas missing read_parquet function in Azure Databricks
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Result = [] data = pd.read_parquet(file) for index in data.index: Web september 9, 2022. Web in this article, we covered two methods for reading partitioned parquet files in python: Using pandas’ read_parquet() function and using pyarrow’s.

Solved pandas read parquet from s3 in Pandas SourceTrail
Web in this article, we covered two methods for reading partitioned parquet files in python: Using pandas’ read_parquet() function and using pyarrow’s. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. While csv files may be the. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable.
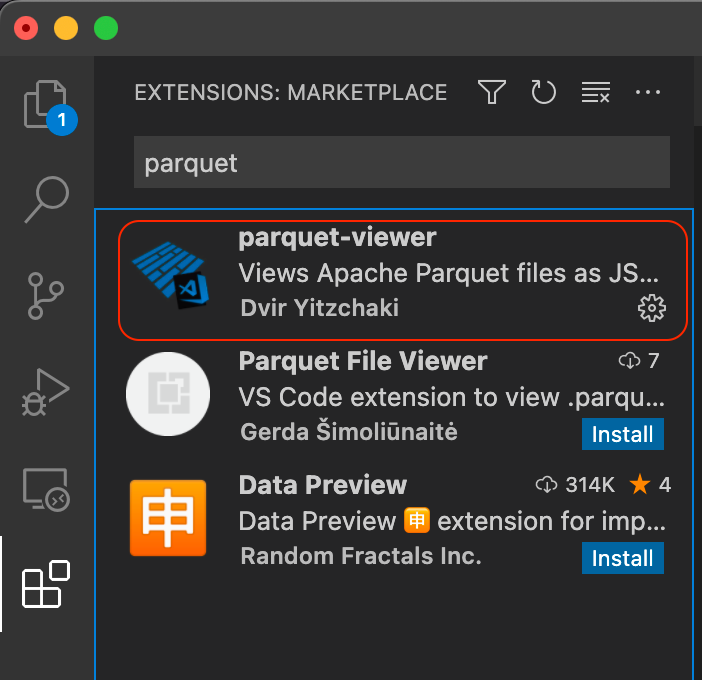
How to read (view) Parquet file ? SuperOutlier
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Using pandas’ read_parquet() function and using pyarrow’s. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. When using the 'pyarrow' engine and no storage options.
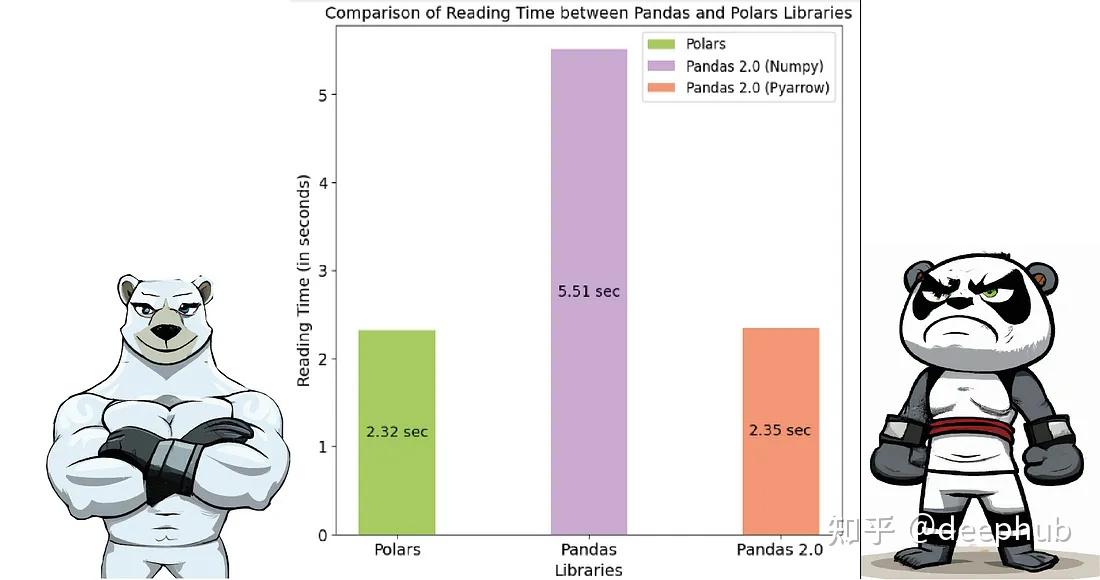
Pandas 2.0 vs Polars速度的全面对比 知乎
In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. Result = [] data = pd.read_parquet(file) for index in data.index: When using the 'pyarrow' engine and no storage options. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Web in this article, we covered.
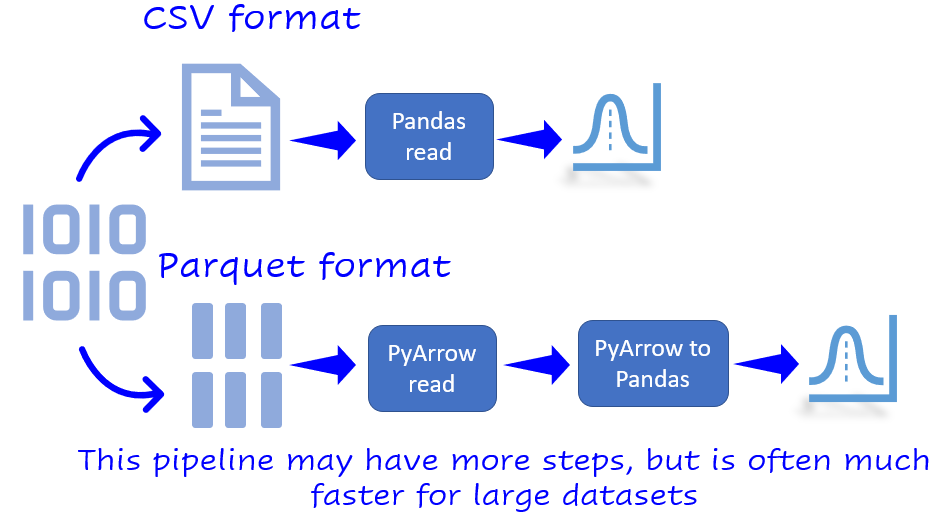
Why you should use Parquet files with Pandas by Tirthajyoti Sarkar
Using pandas’ read_parquet() function and using pyarrow’s. Web september 9, 2022. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Result = [] data = pd.read_parquet(file) for index in data.index:
Is there a way to open and read the content of the parquet files
Web 1.install package pin install pandas pyarrow. While csv files may be the. Web september 9, 2022. Web in this article, we covered two methods for reading partitioned parquet files in python: Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable.

python How to read parquet files directly from azure datalake without
Web 1.install package pin install pandas pyarrow. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Result = [] data = pd.read_parquet(file) for index in data.index: In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas.

pd.read_parquet Read Parquet Files in Pandas • datagy
When using the 'pyarrow' engine and no storage options. Result = [] data = pd.read_parquet(file) for index in data.index: While csv files may be the. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas.
Cannot read ".parquet" files in Azure Jupyter Notebook (Python 2 and 3
Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Web september 9, 2022. Using pandas’ read_parquet() function and using pyarrow’s. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas. Result = [] data = pd.read_parquet(file) for index in data.index:
Web September 9, 2022.
Web in this article, we covered two methods for reading partitioned parquet files in python: Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default,. Using pandas’ read_parquet() function and using pyarrow’s. Result = [] data = pd.read_parquet(file) for index in data.index:
When Using The 'Pyarrow' Engine And No Storage Options.
Web 1.install package pin install pandas pyarrow. While csv files may be the. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. In this tutorial, you’ll learn how to use the pandas read_parquet function to read parquet files in pandas.