Pd Read Parquet
Pd Read Parquet - From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… You need to create an instance of sqlcontext first. Web pandas 0.21 introduces new functions for parquet: Web sqlcontext.read.parquet (dir1) reads parquet files from dir1_1 and dir1_2. Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or. Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet… Web the data is available as parquet files. I get a really strange error that asks for a schema:
Web the data is available as parquet files. You need to create an instance of sqlcontext first. Web 1 i'm working on an app that is writing parquet files. From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… Any) → pyspark.pandas.frame.dataframe [source] ¶. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. This function writes the dataframe as a parquet. Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function.
Right now i'm reading each dir and merging dataframes using unionall. A years' worth of data is about 4 gb in size. Is there a way to read parquet files from dir1_2 and dir2_1. Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or. Write a dataframe to the binary parquet format. Import pandas as pd pd.read_parquet('example_fp.parquet', engine='fastparquet') the above link explains: Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Web the data is available as parquet files. Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. This function writes the dataframe as a parquet.

Parquet from plank to 3strip from MEISTER
A years' worth of data is about 4 gb in size. Is there a way to read parquet files from dir1_2 and dir2_1. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. These engines are very similar and should read/write nearly identical parquet. Any) → pyspark.pandas.frame.dataframe [source] ¶.

How to read parquet files directly from azure datalake without spark?
Connect and share knowledge within a single location that is structured and easy to search. This function writes the dataframe as a parquet. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function. Any) → pyspark.pandas.frame.dataframe [source] ¶. For testing purposes, i'm trying to read a generated file with pd.read_parquet.
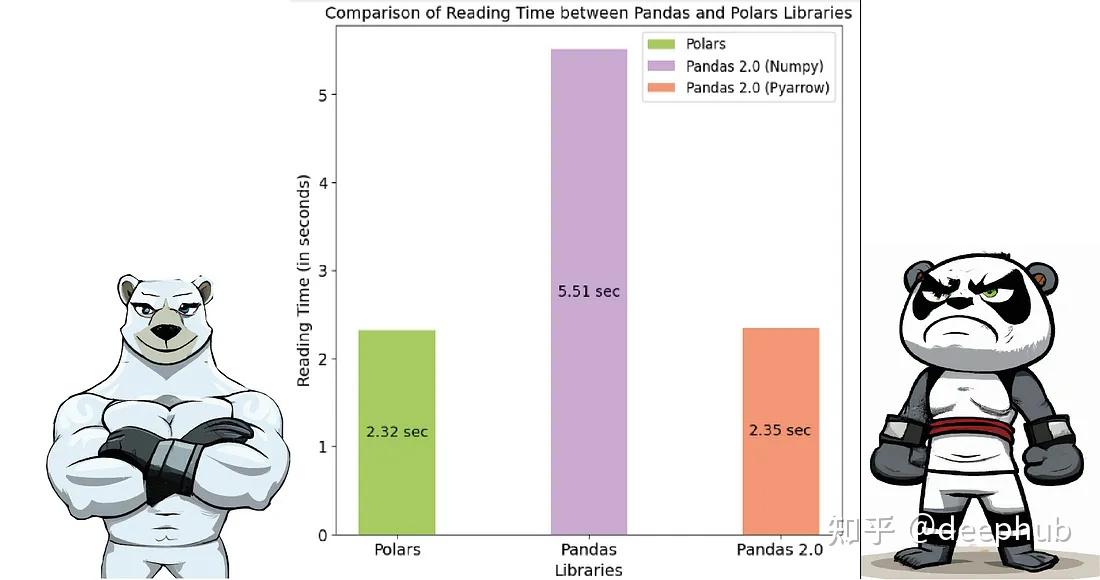
Pandas 2.0 vs Polars速度的全面对比 知乎
Web 1 i'm working on an app that is writing parquet files. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, **kwargs) [source] #. Import pandas as pd pd.read_parquet('example_pa.parquet', engine='pyarrow') or. Any) → pyspark.pandas.frame.dataframe [source] ¶. This will work from pyspark shell:

pd.read_parquet Read Parquet Files in Pandas • datagy
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Is there a way to read parquet files from dir1_2 and dir2_1. You need to create an instance of sqlcontext first. Connect and share knowledge within a single location that is structured and easy to search. Write a dataframe to the binary parquet format.

Spark Scala 3. Read Parquet files in spark using scala YouTube
Any) → pyspark.pandas.frame.dataframe [source] ¶. Connect and share knowledge within a single location that is structured and easy to search. Web dataframe.to_parquet(path=none, engine='auto', compression='snappy', index=none, partition_cols=none, storage_options=none, **kwargs) [source] #. Right now i'm reading each dir and merging dataframes using unionall. Web pandas 0.21 introduces new functions for parquet:

python Pandas read_parquet partially parses binary column Stack
Any) → pyspark.pandas.frame.dataframe [source] ¶. Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… Is there a way to read parquet files from dir1_2 and dir2_1. Web reading parquet to pandas filenotfounderror ask question asked 1 year, 2 months ago modified 1 year, 2 months ago viewed 2k.
PySpark read parquet Learn the use of READ PARQUET in PySpark
Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers, according to a letter sent. Is there a way to read parquet files from dir1_2 and dir2_1. For testing purposes, i'm trying to read a generated file with pd.read_parquet. You need to create an.

Modin ray shows error on pd.read_parquet · Issue 3333 · modinproject
Import pandas as pd pd.read_parquet('example_fp.parquet', engine='fastparquet') the above link explains: Right now i'm reading each dir and merging dataframes using unionall. Web the data is available as parquet files. Any) → pyspark.pandas.frame.dataframe [source] ¶. Web the us department of justice is investigating whether the kansas city police department in missouri engaged in a pattern of racial discrimination against black officers,.

Parquet Flooring How To Install Parquet Floors In Your Home
Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function. Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… It.

How to resolve Parquet File issue
Web pandas.read_parquet(path, engine='auto', columns=none, storage_options=none, use_nullable_dtypes=_nodefault.no_default, dtype_backend=_nodefault.no_default, filesystem=none, filters=none, **kwargs) [source] #. This function writes the dataframe as a parquet. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function. For testing purposes, i'm trying to read a generated file with pd.read_parquet. Right now i'm reading each dir and merging.
I Get A Really Strange Error That Asks For A Schema:
Web to read parquet format file in azure databricks notebook, you should directly use the class pyspark.sql.dataframereader to do that to load data as a pyspark dataframe, not use pandas. Any) → pyspark.pandas.frame.dataframe [source] ¶. Is there a way to read parquet files from dir1_2 and dir2_1. It reads as a spark dataframe april_data = sc.read.parquet ('somepath/data.parquet…
Web Reading Parquet To Pandas Filenotfounderror Ask Question Asked 1 Year, 2 Months Ago Modified 1 Year, 2 Months Ago Viewed 2K Times 2 I Have Code As Below And It Runs Fine.
Right now i'm reading each dir and merging dataframes using unionall. From pyspark.sql import sqlcontext sqlcontext = sqlcontext (sc) sqlcontext.read.parquet (my_file.parquet… Parquet_file = r'f:\python scripts\my_file.parquet' file= pd.read_parquet (path = parquet… You need to create an instance of sqlcontext first.
Web Pandas.read_Parquet(Path, Engine='Auto', Columns=None, Storage_Options=None, Use_Nullable_Dtypes=_Nodefault.no_Default, Dtype_Backend=_Nodefault.no_Default, **Kwargs) [Source] #.
Connect and share knowledge within a single location that is structured and easy to search. Web 1 i'm working on an app that is writing parquet files. A years' worth of data is about 4 gb in size. This will work from pyspark shell:
For Testing Purposes, I'm Trying To Read A Generated File With Pd.read_Parquet.
Web the data is available as parquet files. Web pandas 0.21 introduces new functions for parquet: These engines are very similar and should read/write nearly identical parquet. Web 1 i've just updated all my conda environments (pandas 1.4.1) and i'm facing a problem with pandas read_parquet function.